Confluent’s New Cloud Capabilities Address Data Streaming Hurdles
发布时间: 2023-05-17
Confluent has announced several new Confluent Cloud capabilities and features that address the data governance, security, and optimization needs of data streaming in the cloud.
“Real-time data is the lifeblood of every organization, but it’s extremely challenging to manage data coming from different sources in real time and guarantee that it’s trustworthy,” said Shaun Clowes, chief product officer at Confluent, in a release. “As a result, many organizations build a patchwork of solutions plagued with silos and business inefficiencies. Confluent Cloud’s new capabilities fix these issues by providing an easy path to ensuring trusted data can be shared with the right people in the right formats.”
Confluent’s 2023 Data Streaming Report, also newly released, found that 72% of IT leaders cite the inconsistent use of integration methods and standards as a challenge or major hurdle to their data streaming infrastructure, a problem that led the company to develop these new features.
A New Engine
Right off the bat, the engine powering Confluent Cloud has been reinvented. Confluent says it has spent over 5 million engineering hours to deliver Kora, a new Kafka engine built for the cloud.
(Source: Confluent)
Confluent Co-founder and CEO Jay Kreps penned a blog post explaining how Kora came to be: “When we launched Confluent Cloud in 2017, we had a grand vision for what it would mean to offer Kafka in the cloud. But despite the work we put into it, our early Kafka offering was far from that—it was basically just open source Kafka on a Kubernetes-based control plane with simplistic billing, observability, and operational controls. It was the best Kafka offering of its day, but still far from what we envisioned.”
Kreps goes on to say that the challenges facing a cloud data system are different from a self-managed open source download, such as the need for scalability, security, and multi-tenancy. Kora was designed with these constraints in mind, Kreps says, as it is multi-tenant first, can be run across over 85 regions in three clouds, and is operated at scale by a small on-call team. Kora disaggregates individual components within the network, compute, metadata, and storage layer, and data locality can be managed between memory, SSDs, and object storage. It is optimized for the cloud environment and the particular workloads of a streaming system in the cloud, and real-time usage is captured to improve operations like data placement and fault detection and recovery, as well as costs for large-scale use.
Krebs says Kora will not displace open source Kafka and the company will continue contributing to the project. Kora is 100% compatible with all currently supported versions of the Kafka protocol. Check out his blog for more details.

(pichetw/Shutterstock)
Data Quality Rules
Data Quality Rules is a new feature in Confluent’s Stream Governance suite that is geared towards the governance of data contracts. Confluent notes that a critical component of data contracts enforcement is the rules or policies that ensure data streams are high-quality, fit for consumption, and resilient to schema evolution over time. The company says it is addressing the need for more comprehensive data contracts with this new feature, and schemas stored in Schema Registry can now be augmented with several types of rules. With Data Quality Rules, values of individual fields within a data stream can be validated and constrained to ensure data quality, and if data quality issues arise, there are customizable follow-up actions on incompatible messages. Schema evolution can be simplified using migration rules to transform messages from one data format to another, according to Confluent.
“High levels of data quality and trust improves business outcomes, and this is especially important for data streaming where analytics, decisions, and actions are triggered in real time,” said Stewart Bond, VP of data intelligence and integration software at IDC said in a statement. “We found that customer satisfaction benefits the most from high quality data. And, when there is a lack of trust caused by low quality data, operational costs are hit the hardest. Capabilities like Data Quality Rules help organizations ensure data streams can be trusted by validating their integrity and quickly resolving quality issues.”
Custom Connectors
Instead of relying on self-managed custom-built connectors that require manual provisioning, upgrading, and monitoring, Confluent is now offering Custom Connectors to enable any Kafka connector to run on Confluent Cloud without infrastructure management. Teams can connect to any data system using their own Kafka Connect plugins without code changes, and there are built-in observability tools to monitor the health of the connectors. The new Custom Connectors are available on AWS in select regions with support for additional regions and cloud providers coming soon.
“To provide accurate and current data across the Trimble Platform, it requires streaming data pipelines that connect our internal services and data systems across the globe,” said Graham Garvin, product manager at Trimble. “Custom Connectors will allow us to quickly bridge our in-house event service and Kafka without setting up and managing the underlying connector infrastructure. We will be able to easily upload our custom-built connectors to seamlessly stream data into Confluent and shift our focus to higher-value activities.”
Stream Sharing
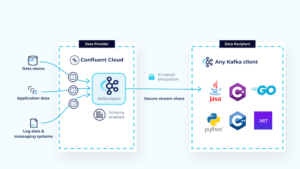
Confluent’s Stream Sharing allows topics in Kafka to be shared. (Source: Confluent)
For organizations that exchange real-time data internally and externally, relying on flat file transmissions or polling APIs for data exchange could result in security risks, data delays, and integrations complexity, Confluent asserts. Stream Sharing is a new feature that allows users to exchange real-time data directly from Confluent to any Kafka client with security capabilities like authenticated sharing, access management, and layered encryption controls.
In Kafka, a topic is a category or feed that stores messages where producers write data to topics and consumers retrieve it through messages. Stream Sharing allows users to share topics outside of their Confluent Cloud organization between enterprises, and invited consumers can stream shared topics with an existing log-in or a new account using a Kafka client.
 Early Access for Managed Apache Flink
Early Access for Managed Apache Flink
Confluent is also debuting is a new early access program. Apache Flink is often chosen by customers for querying large-scale, high throughput data streams, and it operates as a service at the cloud layer. Confluent recently acquired Immerok, developer of a cloud-native and fully managed Flink service for large-scale data stream processing. At the time of the acquisition, Confluent announced it had plans to launch its own fully managed Flink service compatible with Confluent Cloud. The time has come: Confluent has opened an early access program for managed Apache Flink to select Confluent Cloud customers. The company says this program will allow customers to try the service and help shape the roadmap by partnering with the company’s product and engineering teams.
For a full rundown of Confluent’s news, check out Jay Kreps’ keynote from May 16 at Kafka Summit London 2023 here.
Related Items:
Confluent Works to Hide Streaming Complexity
Confluent Delivers New Cluster Controls, Data Connectors for Hosted Kafka
Confluent to Develop Apache Flink Offering with Acquisition of Immerok
-