当前数据市场的数据垄断现状及成因分析
发布时间: 2020-09-28
大数据时代,海量数据的累积催生了数据挖掘、机器学习等新兴技术,同时也为这些技术预测未来、作出决策提供了基础,为社会创造了前所未有的价值。随着数据的累积,数据作为驱动人工智能等技术发展的重要资源,逐渐成为各科技公司争夺的主要对象,不同科技企业在数据资源的储备量上的差异也愈加明显,数据垄断逐渐形成,并催生了“堰塞湖”,各企业间的数据难以互通,并且由于数据本身与个人隐私的密切关系,用户隐私泄露问题亦随之凸显。笔者带领团队基于3000万真实用户数据和30万APP数据,对当前的数据收集情况进行了量化分析发现,当前数据垄断形势异常严峻,对数据进行有效治理迫在眉睫,而数据透明化应是未来数据治理的主题和必经之路。
当前移动应用软件市场的数据垄断现状
为量化当前移动应用市场的数据垄断情况,笔者基于3000万真实用户数据和30万APP数据,使用权限分析法对2018与2019两年大数据收集现状进行分析。分析的主要对象包括:数据生产者,即产生数据的个人或机构,在移动应用场景中通常指移动用户;数据收集者,即以主动或被动的方式收集数据的个人或机构,在移动应用场景中通常指APP开发商;数据使用者,即以任何形式处理或使用数据的个人或机构,在移动应用场景中它可以是数据收集者,也可以是通过数据流通、共享等方式获取数据的第三方;数据监管者,即在数据收集、流通、使用过程中对数据进行合法监管的个人或机构,通常包括相关政府机构和可信第三方等。分析结果显示,当前移动应用市场数据垄断形势十分严峻,10%的数据收集者可获取99%的用户权限数据,数据收集的不平衡现象远甚于社会财富分配中的二八定律。
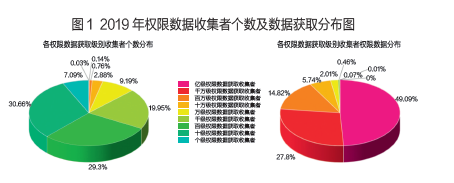
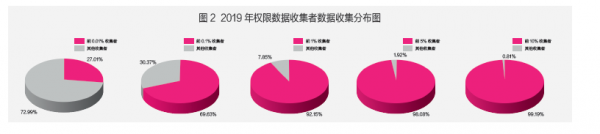
首先,从总体数据垄断现状来看,为详细阐明该数据收集现状,笔者根据获取权限数据的数量级对数据收集者进行划分,将获取1亿及以上权限数据的收集者定义为“亿级权限数据收集者”,获取1亿以下1千万以上权限数据的数据收集者定义为“千万级权限数据收集者”,并以此类推。主要结论如下:根据2019年总体数据收集状况,当前数据垄断形势严峻,极少数数据收集者垄断了绝大部分权限数据。2019年度数据垄断的“主力军”是占据所有数据收集者数量1%的“百万级、千万级、亿级的权限数据收集者”,他们可获取约92%的权限数据。对比2018年度与2019年度数据垄断状况,前10%的权限数据收集者获取的权限数据量占比略有减少,但总体上数据垄断态势居高不下。具体而言,不同级别权限数据收集者的数量与获取数据量的对比分布如图1所示,“百万级、千万级、亿级的权限数据收集者”本身的数量极小,但权限数据获取量均在10%以上,而其余大量的数据收集者可获取的数据量不足3%。该状况从不同比例数据收集者获取权限数据分布情况中体现得更为明显,如图2所示。表1给出2018年度与2019年度权限数据收集的对比情况,其变化量为负值说明这些权限数据收集者获取数据量占比有所减少,但权限数据收集者数量超过5%后,其获取数据量的变化微乎其微。可见,我国总体数据垄断形势依旧严峻。
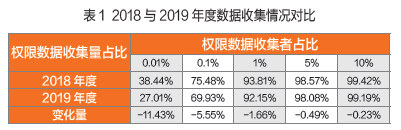
其次,从分类数据垄断现状来看,笔者所在团队对Google Play及国内第三方应用网站中APP分类进行调研,将当前市场上的APP划分为20类,分别是安全类、生活类、社交类、办公类、理财类、购物类、教育类、儿童类、旅游出行类、摄影图片类、视频类、工具类、通信类、新闻类、医疗类、音乐类、游戏类、娱乐类、阅读类和运动类。基于该分类,得出如下结论:每类APP的数据垄断形势都十分严峻,前10%的数据收集者均收集了不少于97%的权限数据。各类APP中,工具类、社交类和游戏类为数据垄断的重灾区,教育类和阅读类的数据垄断状况较总体水平有所缓解。具体情况如图3所示,工具类、社交类和游戏类的前0.1%数据收集者收集了约80%的权限数据,前1%的数据收集者收集了约95%的权限数据,而前5%的数据收集者就收集了约99%的权限数据。在形势较为缓和的教育类和阅读类,前1%的数据收集者收集了约75%的权限数据,低于该比例数据收集者对应的总体占比。
最后,从主要数据收集者垄断现状来看,笔者对数据获取量排名前5的数据收集者对比分析,以展示当前主要数据收集者的垄断现状。为保护数据收集者的个体隐私,该分析隐藏这5个数据收集者的名称,仅提供统计性结果。这5个数据数据者,最多的可获取8%的权限数据,最少者可获取3%的权限数据,累计可获取近24%的数据。也就是说,仅这5个数据收集者,就可获取约1/4的用户数据。其中,3个数据收集者所开发APP涉及了18个以上的APP类别,其余2个数据收集者侧重于单个领域,其开发APP仅涉及了不足5个类别。这5个数据收集者的共同点是:其开发APP对应的用户量群体均十分庞大。
以当前数据收集者们的数据获取量为依据,分析数据垄断的成因
在严峻的数据垄断形势下,探究数据垄断成因十分关键。当前数据垄断的形成与数据自身的特点、数据收集者们的商业运营模式以及人工智能时代的网络效应密切相关。
第一,数据易聚集、难确权的特性,使得数据垄断易形成。大数据时代,海量数据通过移动设备、传感器网络等源源不断地自动产生,数据的生产成本较低,同时其本身的价值密度也较低,海量数据的价值需通过数据挖掘、机器学习等技术提取。而这些技术本质上是数据驱动型技术,需基于大量数据的输入才能获取高准确性、高可用性的输出结果,造成数据本身易聚集的特点。此外,数据本身的特殊性使其既不同于石油、矿藏类的自然产物,也不同于专利、作品等精神产物,难以确定其所有权。在当前数据不能依据法律法规确权的现状下,数据收集的合理合规性得不到有效保证,易形成数据垄断。
第二,数据寡头多产品、跨领域、高用户量的商业运营特点,是数据垄断形成的重要因素。数据寡头即当前数据垄断的主要对象,对应的就是排名前0.1%的数据收集者。当前数据寡头们通过业务扩张、资本运作、并购等方式完成企业扩张,导致其具有多产品、跨领域的商业特点,并据此吸引或维系海量用户,从而具有海量数据收集的能力,形成数据垄断。分析结果表明,在移动应用市场,数据收集者们开发APP的数量越多、使用量越高、涉足的领域越多,其获取的权限数据量越大,越有可能成为数据寡头,形成数据垄断。显然,前0.1%的权限数据收集者的这三个因素比其他权限数据收集者明显高出数倍。
第三,人工智能时代的网络效应促进数据垄断形成。人工智能技术数据驱动的特点使其本身就具有网络效应。随着人工智能技术产品使用的用户量激增,该技术可获取更多用户的数据输入,从而可创建可用性更高的数据模型,增加其自身价值的同时吸引并服务于更多用户。当前移动应用市场上的数据寡头均为大型科技公司,他们均受益于人工智能等技术的支持。相应地,基于其海量的用户数据,他们可持续发展优化其产品与服务,进一步维持并吸引新用户。而本身处于弱势的数据收集者们则限于其产品或服务的升级能力,迫于数据寡头发展的压力逐渐流失用户,滚雪球效应产生,数据垄断现象随之加剧。
本文内容转载自:人民论坛 rmlt.com.cn
原文作者:孟小峰 中国人民大学信息学院教授、博导
原文地址: http://www.rmlt.com.cn/2020/0925/594487.shtml
孟小峰 中国人民大学信息学院教授、博导